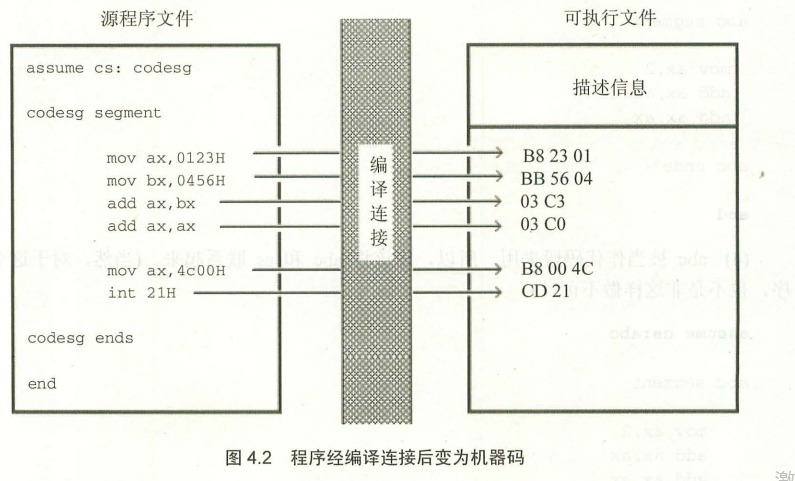
##汇编程序从写出到执行的过程
编程-> 1.asm -> 编译 masm -> 1.obj -> 连接(link)-> 1.exe-> 加载 (command) -> 内存中的程序 -> 运行(run) CPU
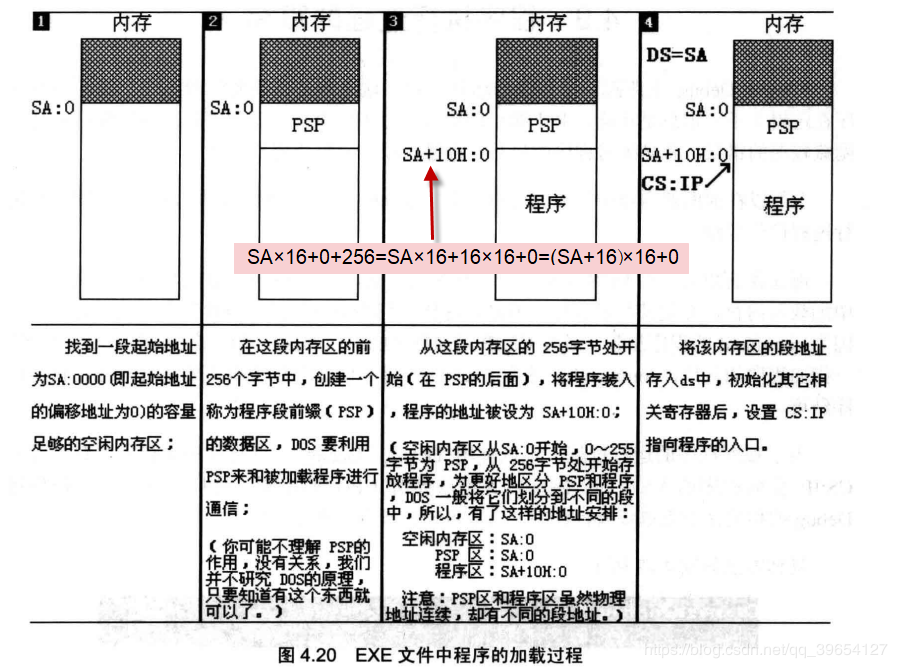
加载后,CPU的CS:IP指向程序的第一条指令(即程序的入口)
限于篇幅,其实只要拿一个实例就懂了
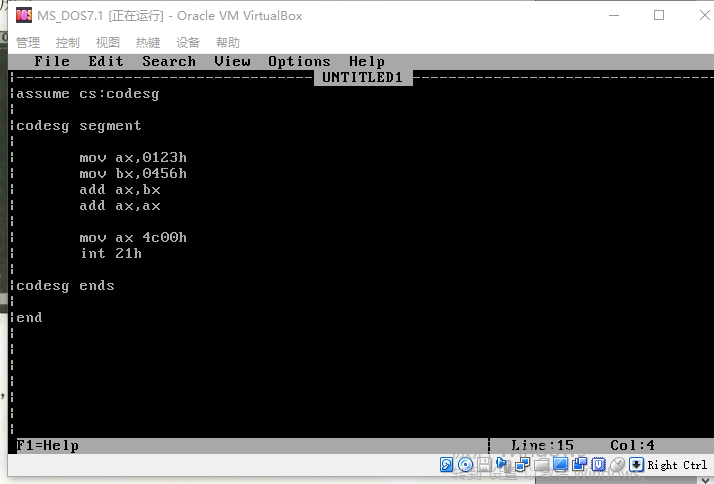
;1.asm
assume cs:codesg ;将用作代码段的段codesg和段寄存器cs联系起来。
codesg segment ;定义一个段,段的名称为“codesg”,这个段从此开始
;codesg是一个标号,作为一个段的名称,最终被编译连接成一个段的段地址
mov ax, 0123H
mov bx, 0456H
add ax, bx
add ax, ax
mov ax, 4c00H
int 21H ;这两条指令实现程序的返回
codesg ends ;名称为“codesg”的段到此结束
end ;编译器在编译汇编程序的过程中,碰到了伪指令end,结束对源程序的编译
这段代码里面有伪指令,伪指令需要编译器来执行的。
(1)
xxx segment
.....
.....
xxx ends
这个就不细说了,一个段开始,结束,必须要段名称,该程序的段名称是codesg,书中也说codesg也是标号
(2)
end
这个也是伪指令
(3)
assume
这个也是伪指令, 假设的意思,详细入注释所说,关联相关的段寄存器而已
编译后的示意图(汇编-机器码)
##程序执行过程跟踪
DOS系统中.EXE文件中的程序的加载过程
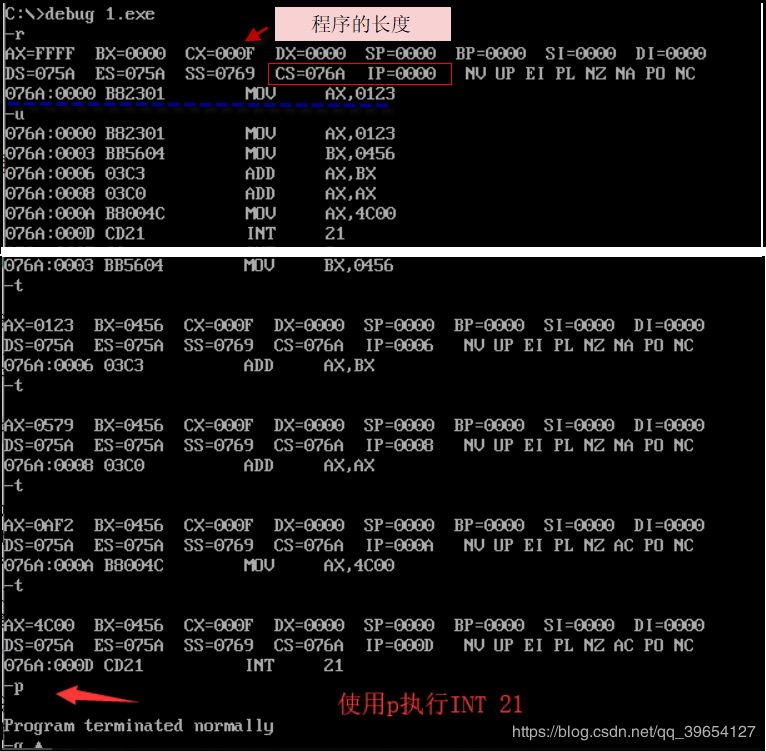
[bx]和loop指令
[bx]和loop指令
[bx] 的含义:[bx]同样表示一个内存单元,它的偏移地址在bx中,段地址默认在ds中
loop指令的格式是:loop 标号,CPU执行loop指令的时候,要进行两步操作,
(cx) =(cx) - 1;
判断cx中的值,不为零则转至标号处执行程序,如果为零则向下执行。 计算 $\2^12$ 2的12次幂。
assume cs:code
code segment
mov ax, 2
mov cx, 11 ;循环次数
s: add ax, ax
loop s ;在汇编语言中,标号代表一个地址,标号s实际上标识了一个地址,这个地址处有一条指令:add ax,ax。
;执行loops时,首先要将(cx)减1,然后若(cx)不为0,则向前
;转至s处执行add ax,ax。所以,可以利用cx来控制add ax,ax的执行次数。
mov ax,4c00h
int 21h
code ends
end
##loop和[bx]的联合应用
计算ffff:0 ~ ffff:b单元中的数据的和,结果存储在dx中
问题分析:
- 这些内存单元都是字节型数据范围0 ~ 255 ,12个字节数据和不会超过65535,dx可以存下
- 对于8位数据不能直接加到 dx 解决方案:
用一个16位寄存器来做中介。将内存单元中的8位数据赋值到一个16位寄存器a中,再将ax中的数据加到dx
assume cs:code
code segment
mov ax, 0ffffh ;在汇编源程序中,数据不能以字母开头,所以要在前面加0。
mov ds, ax
mov bx, 0 ;初始化ds:bx指向ffff:0
mov dx, 0 ;初始化累加寄存器dx,(dx)= 0
mov cx, 12 ;初始化循环计数寄存器cx,(cx)= 12
s: mov al, [bx]
mov ah, 0
add dx, ax ;间接向dx中加上((ds)* 16 +(bx))单元的数值
inc bx ;ds:bx指向下一个单元
loop s
mov ax, 4c00h
int 21h
code ends
end
段前缀
mov ax, ds:[bx]
mov ax, cs:[bx]
mov ax, ss:[bx]
mov ax, es:[bx]
mov ax, ss:[0]
mov ax, cs:[0]
这些出现在访问内存单的指令中,用于显式地指明内存单元的段地址 的“ds:”,“cs:”,“ss:”,“es:”,在汇编语言中称为段前缀。
段前缀的使用
将内存ffff:0 ~ ffff:b单元中的数据复制到0:200 ~ 0:20b单元中。
ssume cs:code
code segment
mov ax, 0ffffh
mov ds, ax ;(ds)= 0ffffh
mov ax, 0020h
mov es, ax ;(es)= 0020h
mov bx, 0 ;(bx)= 0,此时ds:bx指向ffff:0,es:bx指向0020:0
mov cx,12 ;(cx)=12,循环12次
s: mov dl,[bx] ;(d1)=((ds)* 16+(bx)),将ffff:bx中的字节数据送入dl
mov es:[bx],dl ;((es)*16+(bx))=(d1),将dl中的数据送入0020:bx
inc bx ;(bx)=(bx)+1
loop s
mov ax,4c00h
int 21h
code ends
end
##包含多个段的程序
程序中对段名的引用,将被编译器处理为一个表示段地址的数值。
1.在一个段中存放数据、代码、栈的情况。 2.将数据、代码、栈放入不同的段中。
在代码段中使用数据 计算8个数据的和存到ax寄存器,且数据是给定的,自然要考虑给定数据存放在哪里的问题
代码如下:
;计算8个数据的和存到ax寄存器
assume cs:code
code segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h ;define word 定义8个字形数据
start: mov bx, 0 ;标号start
mov ax, 0
mov cx, 8
s: add ax, cs:[bx]
add bx, 2
loop s
mov ax, 4c00h
int 21h
code ends
end start ;end除了通知编译器程序结束外,还可以通知编译器程序的入口在什么地方
;用end指令指明了程序的入口在标号start处,也就是说,“mov bx,0”是程序的第一条指令。
dw 是定义字型数据 define word,8个数据,占用的内存空间大小是16个字节。
注:end除了通知编译器程序结束外,还可以通知编译器程序的入口在什么地方,注释有说明。
代码里面有个start 标号,就如注释所说,指定程序入口,否的话,默认程序入口就是dw 定义8个字节说的地址,可这些存放的都是数据,并不是指令码,一旦执行,会导致程序崩溃!
在代码段中使用栈
assume cs:codesg
codesg segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h ;0-15单元
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
;用dw定义16个字型数据,在程序加载后,将取得16个字的
;内存空间,存放这16个数据。在后面的程序中将这段空间当作栈来使用
;16-47单元作为栈使用
start: mov ax, cs
mov ss, ax
mov sp, 30h ;将设置栈顶ss:sp指向栈底cs:30。 30h = 48d
mov bx, 0
mov cx, 8
s: push cs:[bx]
add bx, 2
loop s ;以上将代码段0~15单元中的8个字型数据依次入栈
mov bx, 0
mov cx, 8
s0: pop cs:[bx]
add bx,2
loop s0 ;以上依次出栈8个字型数据到代码段0~15单元中
mov ax,4c00h
int 21h
codesg ends
end start ;指明程序的入口在start处
我们需要考虑要将用多个段来存放数据、代码和栈
assume cs:code,ds:data,ss:stack
data segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h ;0-15单元
data ends
stack segment
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 ;0-31单元
stack ends
code segment
start: mov ax, stack;将名称为“stack”的段的段地址送入ax
mov ss, ax
mov sp, 20h ;设置栈顶ss:sp指向stack:20。 20h = 32d
mov ax, data ;将名称为“data”的段的段地址送入ax
mov ds, ax ;ds指向data段
mov bx, 0 ;ds:bx指向data段中的第一个单元
mov cx, 8
s: push [bx]
add bx, 2
loop s ;以上将data段中的0~15单元中的8个字型数据依次入栈
mov bx, 0
mov cx, 8
s0: pop [bx]
add bx, 2
loop s0 ;以上依次出栈8个字型数据到data段的0~15单元中
mov ax, 4c00h
int 21h
code ends
end start
;“end start”说明了程序的入口,这个入口将被写入可执行文件的描述信息,
;可执行文件中的程序被加载入内存后,CPU的CS:IP被设置指向这个入口,从而开始执行程序中的第一条指令
再次提醒,CPU 不允许把数据直接存放到ds段寄存器的,通过中间寄存器中转
##更灵活的定位内存地址的方法
and和or
and指令:逻辑与指令,按位进行与运算。
mov al, 01100011B
and al, 00111011B
执行后:al=00100011B即都为1才为1
or指令:逻辑或指令,按位进行或运算。
mov al, 01100011B
or al, 00111011B
执行后:al=01111011B 即只要有一个为1就为1
关于ASCII码,我就不多说了,可以直接查看ASCII表就知道了。
以字符形式给出的数据
assume cs:code,ds:data
data segment
db 'unIx' ;相当于“db 75H,6EH,49H,58H”
db 'foRK'
data ends
code segment
start: mov al, 'a' ;相当于“mov al, 61H”,“a”的ASCI码为61H;
mov b1, 'b'
mov ax, 4c00h
int 21h
code ends
end start
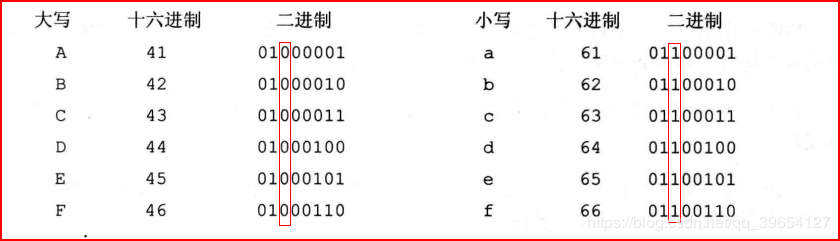
这里可以谈一下大小写转换的问题。 小写字母的ASCII码值比大写字母的ASCII码值大20H。
大写字母ASCII码的第5位为0,小写字母的第5位为1(其他一致)。
代码目的将第一个字符串转化为大写,第二个字符串转化为小写
assume cs:codesg,ds:datasg
datasg segment
db 'BaSiC'
db 'iNfOrMaTion'
datasg end
codesg segment
start: mov ax, datasg
mov ds, ax ;设置ds 指向 datasg段
mov bx, 0 ;设置(bx)=0,ds:bx指向’BaSic’的第一个字母
mov cx, 5 ;设置循环次数5,因为’Basic'有5个字母
s: mov al, [bx];将ASCII码从ds:bx所指向的单元中取出
and al, 11011111B;将al中的ASCII码的第5位置为0,变为大写字母
mov [bx], al ;将转变后的ASCII码写回原单元
inc bx ;(bx)加1,ds:bx指向下一个字母
1oop s
mov bx, 5 ;设置(bx)=5,ds:bx指向,iNfOrMaTion'的第一个字母
mov cx, 11 ;设置循环次数11,因为‘iNfOrMaTion'有11个字母
s0: mov al, [bx]
or al, 00100000B;将a1中的ASCII码的第5位置为1,变为小写字母
mov [bx], al
inc bx
loop s0
mov ax, 4c00h
int 21h
codesg ends
不多说了,直接看注释即可!
###[bx+idata]
[bx+idata]表示一个内存单元, 例如:mov ax, [bx+200]
该指令也可以写成如下格式:
mov ax, [200+bx]
mov ax, 200[bx]
mov ax, [bx].200
用[bx+idata]的方式进行数组的处理
assume cs:codesg,ds:datasg
datasg segment
db 'BaSiC';转为大写
db 'MinIx';转为小写
datasg ends
codesg segment
start:
mov ax, datasg
mov ds, ax
mov bx, 0 ;初始ds:bx
mov cx, 5
s: mov al, 0[bx]
and al, 11011111b ;转为大写字母
mov 0[bx], al ;写回
mov al, 5[bx] ;[5 + bx]
or al, 00100000b ;转为小写字母
mov 5[bx], al
inc bx
loop s
mov ax, 4c00h
int 21h
codesg ends
end start
等效C 语言如下:
int main()
{
char a[] = "BaSic";
char b[] = "MinIX";
int i = 0;
do
{
a[i] = a[i] & 0xDF;
b[i] = b[i] | 0x20;
i++;
} while(i < 5);
return 0;
}
###SI和DI si和di是8086CPU中和bx功能相近的寄存器,si和di不能够分成两个8位寄存器来使用。
以下三组指令是相同的!
-
mov bx,0` mov ax,[bx] ` -
mov si,0` mov ax,[si] ` -
mov di,0` mov ax,[di] `
用si 和 di 实现将字符串’welcome to masm!’ 复制到他后面的数据区中。
assume cs: codesg, ds: datasg
datasg segment
db 'welcome to masm!';用si和di实现将字符串‘welcome to masm!"复制到它后面的数据区中。
db '................'
datasg ends
codesg segment
start: mov ax, datasg
mov ds, ax
mov si, 0
mov cx, 8
s: mov ax, 0[si] ;[0 + si]
mov 16[si], ax ;[16 + si]
add si, 2
loop s
mov ax, 4c00h
int 21h
codesg ends
end start
###[bx + si]和[bx + di]
[bx+si]和[bx+di]的含义相似
[bx+si]表示一个内存单元,它的偏移地址为(bx)+(si)
指令mov ax, [bx + si]的含义:将一个内存单元字数据的内容送入ax,段地址在ds中
该指令也可以写成如下格式:mov ax, [bx][si]
###[bx+si+idata]和[bx+di+idata] [bx+si+idata]表示一个内存单元,它的偏移地址为(bx)+(si)+idata
指令mov ax,[bx+si+idata]的含义:将一个内存单元字数据的内容送入ax,段地址在ds中。
不同的寻址方式的灵活应用
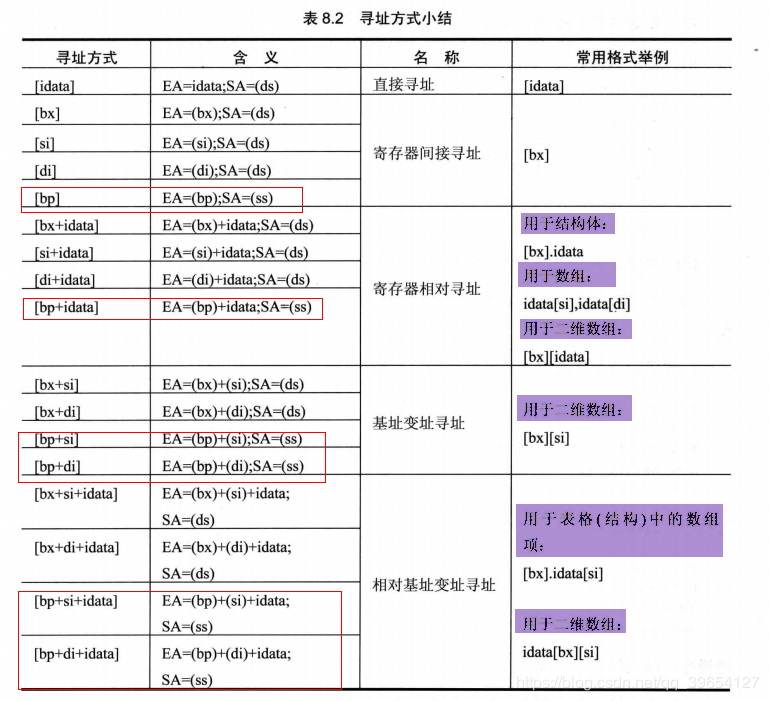
[idata]用一个常量来表示地址,可用于直接定位一个内存单元; [bx]用一个变量来表示内存地址,可用于间接定位一个内存单元; [bx+idata]用一个变量和常量表示地址,可在一个起始地址的基础上用变量间接定位一个内存单元; [bx+si]用两个变量表示地址; [bx+si+idata]用两个变量和一个常量表示地址。
代码示例如下:
;将datasg段中每个单词改为大写字母
assume cs:codesg,ds:datasg,ss:stacksg
datasg segment
db 'ibm ' ;16个数据
db 'dec '
db 'dos '
db 'vax ' ;看成二维数组
datasg ends
stacksg segment ;定义一个段,用来做栈段,容量为16个字节
dw 0, 0, 0, 0, 0, 0, 0, 0
stacksg ends
codesg segment
start: mov ax, stacksg
mov ss, ax
mov sp, 16 ;ss:sp指向栈底
mov ax, datasg
mov ds, ax
mov bx, 0 ;初始ds:bx
;cx为默认循环计数器,二重循环只有一个计数器,所以外层循环先保存cx值,再恢复,我们采用栈保存
mov cx, 4
s0: push cx ;将外层循环的cx值入栈
mov si, 0
mov cx, 3 ;cx设置为内层循环的次数
s: mov al, [bx+si]
and al, 11011111b ;每个字符转为大写字母
mov [bx+si], al
inc si
loop s
add bx, 16 ;下一行
pop cx ;恢复cx值
loop s0 ;外层循环的loop指令将cx中的计数值减1
mov ax,4c00H
int 21H
codesg ends
end start
##数据处理的两个基本问题 reg表示寄存器 sreg表示段寄存器
reg的集合是 ax bx cx dx ah al bh bl ch cl dh dl sp bp si di;
sreg的集合包括 ds ss cs es;
bx、si、di和bp
在8086CPU中,只有这4个寄存器可以用在“[…]”中来进行内存单元的寻址。
在[….. ]中,这4个寄存器可以单个出现,或只能以4种组合出现:bx和si、bx和di、bp和si、bp和di。
只要在[….. ]中使用寄存器bp,而指令中没有显性地给出段地址, 段地址就默认在ss中!
###机器指令处理的数据在什么地方 数据处理大致可分为3类:读取、写入、运算。
在机器指令这一层来讲,并不关心数据的值是多少,而关心指令执行前一刻,它将要处理的数据所在的位置。指令在执行前,所要处理的数据可以在3个地方:CPU内部、内存、端口!

###汇编语言中数据位置的表达
汇编语言中用3个概念来表达数据的位置
- 立即数(idata)
mov ax, 1 ;对于直接包含在机器指令中的数据(执行前在CPU的指令缓冲器中)
add bx, 2000h ;在汇编语言中称为:立即数(idata)
or bx, 00010000b
mov al, 'a'
- 寄存器
mov ax, bx ;指令要处理的数据在寄存器中,在汇编指令中给出相应的寄存器名。
mov ds, ax
push bx
mov ds:[0], bx
push ds
mov ss, ax
mov sp, ax
- 段地址(SA)和偏移地址(EA)
;指令要处理的数据在内存中,在汇编指令中可用[X]的格式给出EA,SA在某个段寄存器中。
mov ax, [0]
mov ax, [di]
mov ax, [bx+8]
mov ax, [bx+si]
mov ax, [bx+si+8] ;以上段地址默认在ds中
mov ax, [bp]
mov ax, [bp+8]
mov ax, [bp+si]
mov ax, [bp+si+8] ;以上段地址默认在ss中
mov ax, ds:[bp]
mov ax, es:[bx]
mov ax, ss:[bx+si]
mov ax, cs:[bx+si+8] ;显式给出存放段地址的寄存器
寻址方式,总结一下!
###指令要处理的数据有多长
8086CPU的指令,可以处理两种尺寸的数据,byte和word!
1.通过寄存器名指明要处理的数据的尺寸。 例如: mov al, ds:[0] 寄存器al指明了数据为1字节
2.在没有寄存器名存在的情况下,用操作符Xptr指明内存单元的长度,X在汇编指令中可以为word或byte。 例如:mov byte ptr ds:[0], 1 byte ptr 指明了指令访问的内存单元是一个字节单元。
3.有些指令默认了访问的是字单元还是字节单元 例如,push [1000H],push 指令只进行字操作。
###寻址方式的综合应用
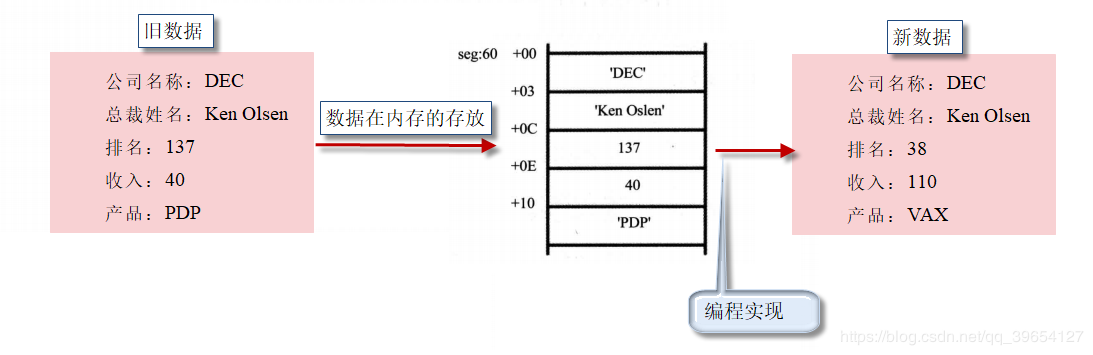
任务就是 编程修改过时的数据
mov ax, seg
mov ds, ax
mov bx, 60h ;确定记录地址,ds:bx
mov word ptr [bx+0ch], 38 ;排名字段改为38 [bx].0ch
add word ptr [bx+0eh], 70 ;收入字段增加70 [bx].0eh
mov si, 0 ;用si来定位产品字符串中的字符
mov byte ptr [bx+10h+si], 'V' ;[bx].10h[si]
inc si
mov byte ptr [bx+10h+si], 'A'
inc si
mov byte ptr [bx+10h+si], 'X'
c语言写法:
/*定义一个公司记录的结构体*/
struct company
{
char cn[3];/*公司名称*/
char hn[9];/*总裁姓名*/
int pm;/*排名*/
int sr;/*收入*/
char cp[3];/*著名产品*/
};
//sizeof (struct company) == 24
int main()
{
/*定义一个公司记录的变量,内存中将存有一条公司的记录*/
struct company dec = {"DEC", "Ken 0lsen", 137, 40, "PDP"};
int i;
dec.pm = 38;
dec.sr = dec.sr + 70;
i = 0;
dec.cp[i] = 'V'; //mov byte ptr [bx].10h[si], 'V'
i++;
dec.cp[i] = 'A';
i++;
dec.cp[i] = 'X';
return 0;
}
div指令、dd、dup、mul指令
###div是除法指令
1.除数:有8位和16位两种,在一个寄存器或内存单元中。
2.被除数:默认放在AX或DX和AX中,如果除数为8位,被除数则为16位,默认在AX中存放; 如果除数为16位,被除数则为32位,在DX和AX中存放,DX存放高16位,AX存放低16位。
3.结果:如果除数为8位,则AL存储除法操作的商,AH存储除法操作的余数; 如果除数为16位,则AX存储除法操作的商,DX存储除法操作的余数。
可能有的对数学不清楚。被除数÷除数=商( 余数); 图片所示:

编程,利用除法计算指令计算100001/100。
分析一下,100001 大于65536, 所以一个ax寄存器不够的,这个只能存放2个字节! 需要dx 和 ax 联合存放! 除数100 小于255,可以放在8位寄存器存放,但是被除数是32位,所以除数一定要用16位的哦!
换算10001 十六进制是186A1H。
如下编码:
;利用除法指令计算100001/100。
mov dx, 1
mov ax, 86A1H ;(dx)*10000H+(ax)=100001
mov bx, 100
div bx
正如书中所说,ax存商,即 (ax) = 03E8H (1000),(dx)=1(余数为1)
作者书中约定过了(ax) 带括号代表ax 里面的值。
;利用除法指令计算1001/100
mov ax, 1001
mov bl, 100
div b1
伪指令dd
db和dw定义字节型数据和字型数据。
dd是用来定义dword(double word,双字)型数据的伪指令
操作符dup
dup在汇编语言中同db、dw、dd等一样,也是由编译器识别处理的符号! 它是和db、dw、dd等数据定义伪指令配合使用的,用来进行数据的重复!
db 3 dup(0) ;定义了3个字节,它们的值都是0,相当于db 0,0,0。
db 3 dup(0, 1, 2) ;定义了9个字节,它们是0、1、2、0、1、2、0、1、2,相当于db 0,1,2,0,1,2,0,1,2。
db 3 dup('abc', 'ABC') ;定义了18个字节,它们是abcABCabcABCabcABCC,相当于db 'abc', 'ABC' ,'abc' , 'ABC, 'abc', 'ABC'。
dup的格式就是如下。 db 重复次数 dup (重复的字节型数据) dw 重复次数 dup (重复的字型数据) dd 重复次数 dup (重复的双字型数据)
###mul 指令 mul是乘法指令,使用 mul 做乘法的时候:相乘的两个数:要么都是8位,要么都是16位。
-
8 位: AL中和 8位寄存器或内存字节单元中;
-
16 位: AX中和 16 位寄存器或内存字单元中。
结果
-
8位:AX中;
-
16位:DX(高位)和AX(低位)中。
格式:mul 寄存器 或 mul 内存单元
;计算100*10
;100和10小于255,可以做8位乘法
mov al,100
mov bl,10
mul bl
;结果: (ax)=1000(03E8H)
;计算100*10000
;100小于255,可10000大于255,所以必须做16位乘法,程序如下:
mov ax,100
mov bx,10000
mul bx
;结果: (ax)=4240H,(dx)=000FH (F4240H=1000000)
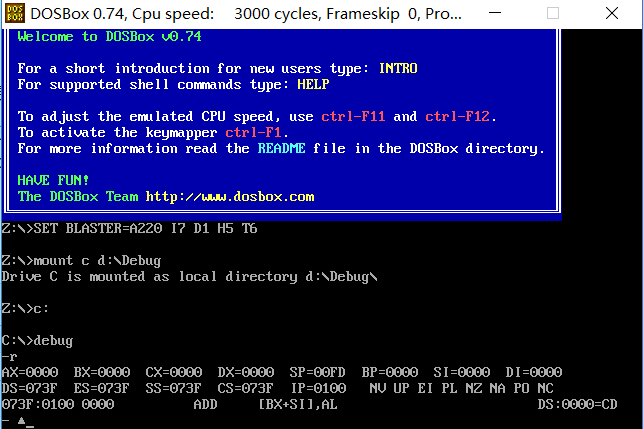
##另附上win10 运行dos debug 和 masm的方法##
就不需要用虚拟机弄,debug里面已经自带了masm
First
首先我们需要给电脑配置debug文件,以win10为例,默认条件下系统没有debug相关的文件,我们需要自己去配置
下载文件我已经上传了,链接在这里
下载好并解压,结果如下:
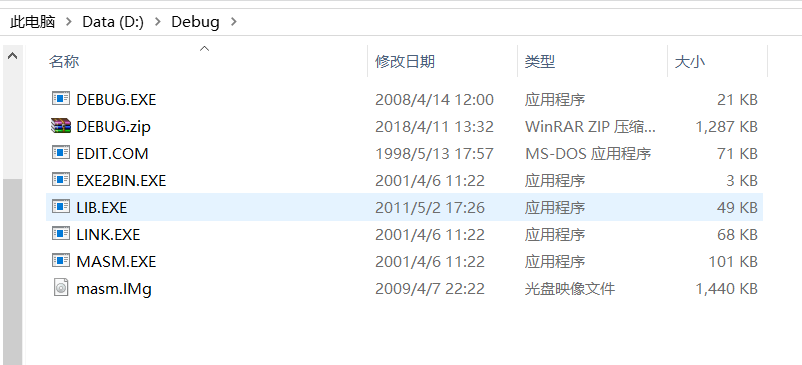 此时我们需要记下当前的路径,我们这里当前路径为D:\Debug
此时我们需要记下当前的路径,我们这里当前路径为D:\Debug
###Second
我们需要下载一个DosBox,根据维基百科上定义讲:
DOSBox是一种模拟器软件,主要是在IBM PC兼容机下,模拟旧时的操作系统:MS-DOS,支持许多IBM PC兼容的显卡和声卡,为本地的DOS程序提供执行环境,使这些程序可以正常运行于大多数现代计算机上的不同操作系统。DOSBox特别是为运行早期的计算机游戏所设计,主要以C++编写,是以GNU通用公共许可证许可发布的自由软件。
DOSBox可以运行那些在现代计算机上不能运行的MS-DOS软件,这些软件通常与现在的主流硬件和操作系统有一些不兼容。DOSBox在模拟MS-DOS同时,还增加了一些可用特性,包括虚拟磁盘、点对点网络、对模拟画面截图和录像。有些非官方的DOSBox变体,如DOSBox SVN Daum和DOSBox SVN-lfn提供了更多的功能,比如存档、长文件名支持等[4]。有些游戏开发商重新发行早期的DOS游戏时,也会使用DOSBox,使其可以在现代计算机上运行。
文件我已经上传到本地了,下载链接在这里
下载后的界面如下:
 Third
我们需要使用mount命令(用来挂载硬盘或镜像等),将DEBUG.EXE所在的路径挂载到C盘的盘符,以便调用的时候方便直接在同一目录下
然后我们只需要输入C:\进入当前的盘符,使用debug命令即可直接启动DEBUG.EXE
Third
我们需要使用mount命令(用来挂载硬盘或镜像等),将DEBUG.EXE所在的路径挂载到C盘的盘符,以便调用的时候方便直接在同一目录下
然后我们只需要输入C:\进入当前的盘符,使用debug命令即可直接启动DEBUG.EXE